

The Road to Seamless Data Movement: Insights from a Data PM on mastering data movement requirements

Happy New Year, Data PMs! Hope you are all set to ring in the new year with some data cheer!
This edition’s topic is about moving data from one system to another. Unless you are a Data PM who works on data integration products, you might often see “data movement” as a solved problem given the number of tools that exist, but let me take this time to tell you it’s not. In this substack, we will discover how to define requirements for a data product that requires any data movement work.
First, some data movement basics.
Data movement refers to the act of moving data from a “source” system to another “destination” system. As you can see below, there could be multiple systems at play here. So, (a) it’s a huge act of “synchronization” i.e. when to read from one system and when to update another system to keep the data accuracy high and, (b) the systems should be compatible i.e. you might want to adhere to some performance in terms of time, frequency of transfer, and the systems should allow for that.
Here’s a chart demonstrating the kind of data movements that you might require i.e. there could be multiple permutations and combinations of various “sources” and “destination” systems.
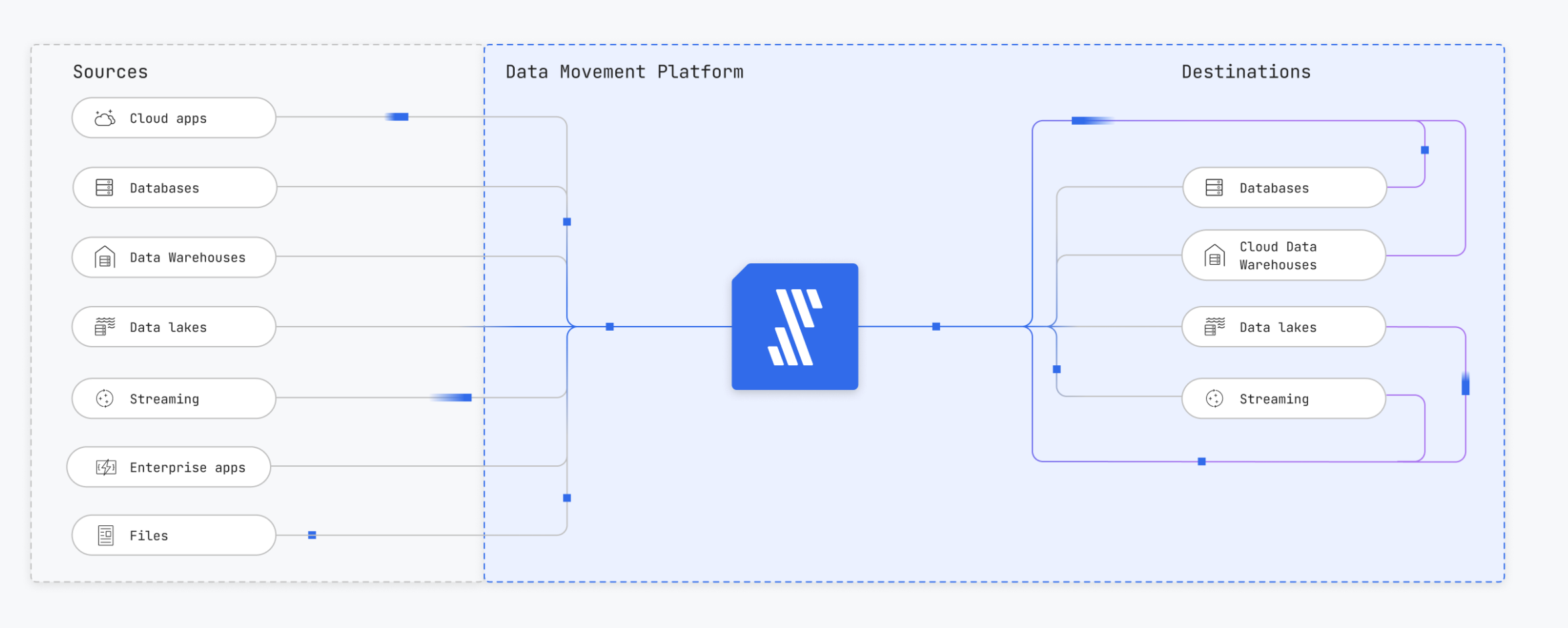
Patterns of data movement based on processes
There are 3 common patterns of data movement. These patterns serve different use cases. Knowing what pattern you are following, helps you determine practical requirements.
ETL: This means Extract, Transform, and Load operations. Usually, this involves extracting data, transforming data (changing data values, creating new fields, summarizing data, etc.), and then loading the data into another system. ETL is useful for very standard/defined analytical workflows. For example, you want to generate a score, so your workflow would be to get source data, do some transformations such as normalization, unit conversion, creating new variables, and then load that data for each customer in a specific way.
ELT: This means extracting the data, loading it as it is, and transforming it a later point. In ELT use cases, the destination system usually is an OLAP system i.e. an analytical system, so could be a Data Lake or Data Warehouse. This is the most useful pattern for Data Science teams who are doing exploratory work, and who don’t know how the “intermediary data” is to be, so they load it first and transform it as required later.
Reverse ETL: This means that typical “Destination” systems like data lakes and warehouses are “source” systems and destination systems are typical “source systems” like apps and production databases. This pattern is a newer pattern and is observed with showing scores/analysis in the “application” itself. For example, you calculated a “health score” or “usage score” for your customers, and now you want to expose that score in the web application, the process of putting that data back in the application would be Reverse ETL. Typically you would treat web application as a “source” to analyze and create internal dashboards, and now the same application is your “destination”



Patterns of data movement based on frequency
Based on whether data updates (changes like edit, add, delete, update of records) is batched or not, there are two types of data movement:
Batch model i.e. updates are sent in batches to another system. Your data movement system will pick up updates at a scheduled interval and dump the data updates in the destination. The most important thing to note is that if you define unrealistic time, then the system will start with a second update even before the first update is done, and will cause data inaccuracies.
In batch models, the atomicity of the data updates matters the most, so that updates are not missed / misread.
Change Data Capture (aka CDC) / Stream / Pub-Sub model i.e. the source system will tell the data movement system that there is a new update for it to pick up. The data movement system will fetch the newer updates make the update in the destination system and maintain a log between the two systems. Here’s how a CDC system works:



Types of Data Movement Systems
Based on these different patterns, a lot of new tools have come up in the market that help with the different data movement requirements, and picking up the best type of tool is important for your product’s success. Matt Turck in the latest MAD Landscape categorizes these tools in the following categories based on patterns of data processing as well as a generic category “data integration” which is more catered towards getting data from apps:

However, this just shows the kind of tools that exist in the industry tool. For a PM to make the right call, what might be worth looking into is how these tools are designed and whether they fit the purpose or not. And, in my opinion, there are three types of data movement tools.
Unopinionated data movement systems - data movement systems that don’t care about the source and the destination schema. Fivetran is a great example of it, as such systems help you pull all the data in the source system, mostly as batches, and then dump the data in the destination system. Here, making sure that data updates are “atomic” is a great binding contact between source and destination. These systems are great for dumping data in an OLAP system.
Opinionated data movement systems - data movement systems that care about the form of the data, and whether the data is being shared in a specific format. These types of data systems are great between applications, to create white-gloved integrations in your product. Merge.dev, Paragon, and Unified.to are great examples, where you can trust the tool to understand the underlying schema and share a specific schema, resulting in better data quality.

Source: Paragon Use-case specific - data movement tools that are built keeping use-cases such as customer 360 or behavioral data plowing in mind, and therefore, might have both batch/stream integrations, can have a loosely modeled schema as well. Eg: Rudderstack, Snowplow, etc.

Source: Rudder Stack


Defining Product Requirements For Data Movement
Now that you understand what kind of solutions exist and what might fit your product requirements, here’s how to best define product requirements for data movement.
Business Use Case: Needless to say, this is the most important consideration. Business case helps to understand why you need to move that data, is it to show a specific score, or do you want to explore data regularly, or do you want to move some data generated from one app to another? Knowing the business case means, knowing the following:
Who will be using the “moved” data i.e. who will be the user? How should the same be presented?
What’s the best way of consuming that information? This would define the type of data movement that is required.
Should it be used exactly as it was in the source or do we need to transform?
Should multiple data points be summarized?
Where all across the product should this information be used?
Data Movement Requirements?
How should the data in the destination be stored or updated to meet all downstream use cases?
How often should that data be updated in the destination system?
What are the performance requirements?
Data update frequency — Should you fetch data from the source system every 5 mins, 10 mins, etc.?
Data movement time — how much time should it take to move one update from source to destination?
Load time at destination - how many seconds/milliseconds should processing each update take?
Storage / IO costs that will add to the product costs.
Data Accuracy — often we don’t specify explicitly what should be the data accuracy expectation - p95 value of matching data between source and destination at any given point of time.
Access control i.e. should all information be accessible to everyone
Metering requirements - should you give control to your customer? What if really big updates are coming your way, which spike up your costs?
Other Considerations
Are your source and destination systems compatible? i.e. can they give the performance you need?
Do you need to build a system internally vs can you use an external system? The classic build vs buy question.
E.g.: Fivetran, Rudderstack, Merge.dev can be leveraged?
Is it cost-effective? The size & frequency of data updates and pricing models should work together. Does the user need to see the updated data at the minimum possible frequency? Or, can you lower the frequency to lower data movement costs?
Do we have the internal bandwidth to build the system? Or, can we use an external tool for MVP?
Are we charging the customer for these integrations? What’s our pricing model around the product?
🔗 Links of the week
Decoding schema: OBT (one big table) vs Star Schema - I genuinely thought I would write about it this week, but then
took care of it.- just released this amazing crash course for Product Strategy, and it’s perfect for any Head of Product or product lead trying to bring together all ideas around product strategy.
Data Engineering Weekly showed me this amazing take by Sanjeev Mohan on AI and Data Trends of 2024! Super useful if you are interviewing right now.
Happy New Year again!🎅
Cheers,
Richa
Your Chief Data Obsessor, The Data PM Gazette.