

Writing a great PRD for Gen AI feature: PART 2

Hey Data PMs!
In the last post, I looked into when and how most companies are using LLM-based features in production: use cases, deployment methods, and how they differ by organization. And, most importantly, what factors can help us define an LLM-based product feature so that we can understand the nature of the solution? To summarize, we talked about the following:
Accuracy
Does this require human input - human in the loop solution?
Solution Complexity and Cost
Data security
Market Timing
Ease of use
As I mulled over further, I found 3 more factors that I wanted to add to the list:
Explainability i.e. how do you explain the results and content that your feature is generating? This is important in a few industries: legal, healthcare, analytics, etc. But, not necessarily, in a chatbot or email/message generation services.
The performance of the model matters too. Promptness of your response will matter in certain situations (eg: chatbot) vs. not matter in another situation (eg: meeting summary). This might make up for solution complexity, but is important to call out.
Fairness i.e. how well your solution works with different prompts and areas of operations. Is it performing better for certain individuals, or groups of individuals, or in certain contexts, does it reflect any biases of the underlying model?
In this substack, we will break down the pre-work required to understand the requirements: what information to gather and how to define the right metrics for your solution.
What information should an AI PM gather?
I spoke to Mahesh, a PM leader at Google who works on Gen AI products. He runs a course on AI Product Management (shameless plug!) to understand what information an AI PM should seek as they write a Gen AI PRD, and he walked me through the considerations he takes while thinking about a Gen AI feature.
I am organizing all the considerations that we talked about into two main buckets: problem space and solution space.
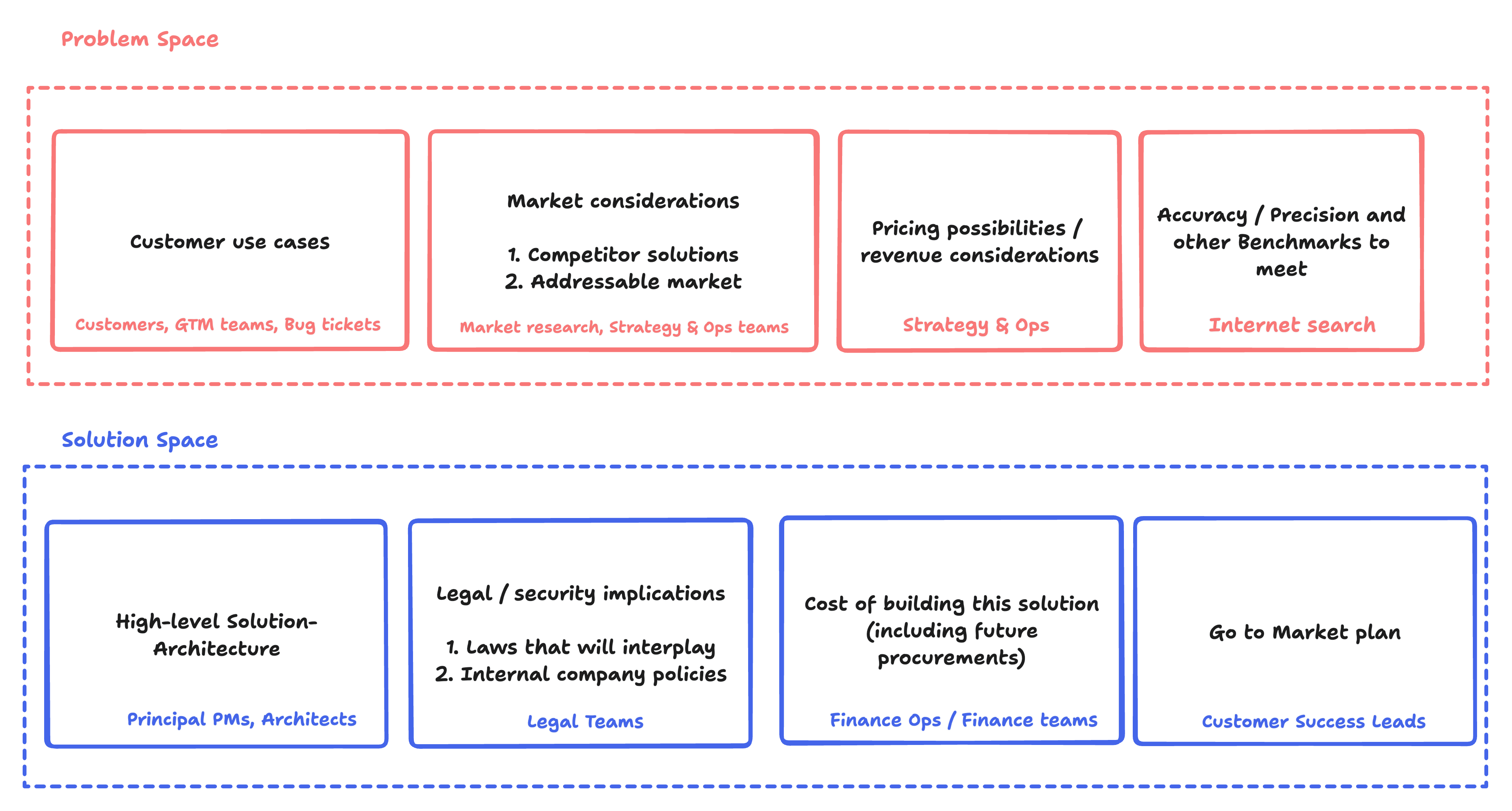
Here’s a checklist of questions to ask yourself/others that can help you gather the right information:
Problem Space
Within the problem space, we will collect information about the use case, how others have solved it, what the market expects from our product, and whether we can price this feature (or not).
Customer Use Cases
What are the use cases I want to cater to with this feature?
What should I not cater to with this feature?
Examples of calls/mentions in deal notes, etc.
Market Considerations
How are my 3 closest competitors solving this problem?
Document their solution
Do they care about explainability, reliability, fairness, etc?
What’s the addressable market for this?
Is it big enough that we should invest the time it would take to build the feature? Why do you think that’s the addressable market?
Do you have signals from the market?
Use competitor pricing x the number of current/potential customers that would benefit from this to understand potential revenue in the short run, and long run.
Pricing possibilities
Can you price that feature? i.e. will it be something you can charge your customers for?
How much does your competitor price it for? What kind of revenue do you expect to generate?
Do I need this to be a “leader” in my category? Is this my differentiated value to the customer?
Benchmarks
What kind of accuracy/precision should you aim for?
E.g. Use GLUE / SQuAD benchmark for Q&A chatbots.
Should my solution be explainable?
Should I be putting out “bias/fairness” results/experiments?
Are there any performance benchmarks that I should be running?
Time to First Response, Task Completion Time / Rate
Use generic LLM benchmarks (see below) to understand performance better.
Solution Space
For the solution space, an AI PM should first create a high-level architecture of the solution so that engineering can understand the scope of implementation, have legal/security considerations laid out, figure out the cost of building the solution, and finally have a go-to-market plan.
High-level architecture
Explain the use cases to an architect/eng lead, and understand what kind of solution you should be building (refer to PART 1), arrive at an overall design of the solution that might look something like this:

High-level architecture for a RAG feature (source) Discover what infrastructure/tooling currently exists and what needs further investment to understand project timelines and procurement requirements
Figure out if there are alternative approaches possible based on sequencing. What are the pros and cons of various approaches?

Security/Legal Considerations
Explain the feature to a security expert and understand whether you should care about laws in a particular region. Eg: GDPR and EU AI act can make your feature unusable in the EU.
Will your use of customer data breach any existing contractual obligations with specific customers?
Do your company’s terms and conditions prevent you from using data for AI modeling, how will you treat Personally Identifiable Information?
The cost of building this solution
Would it be a viable solution in the first place?
Would you need to procure new tools/technologies to build this feature? How would that impact your cost over time?
Is the cost worth the revenue or non-revenue product value: differentiation, market timing, etc.?
Go-to-Market plan
How are you planning to sequence the sub-features for this AI feature?
Which customers would you include in an alpha/beta program? How can customers sign up for the beta?
How will you sequentially build this feature so that the engineering team can sequentially build the desired solution, and you can go to market the fastest, to validate market needs?
Are there any metrics that will define future work? E.g.: Maybe a particular industry-based customer segment might not mind a lower accuracy and can be catered to first.
Would you launch this to all customer segments? Or, some first?
Would you launch this feature in all geographies? Or no?
AI feature metrics
Once you have gathered all the information around the problem and solution space, you should define the right metrics for your feature. Metrics will help you (a) develop a feature that meets market standards, and (b) evaluate if the feature is effective and relevant for your customers.
LLM Performance Metrics
These metrics can be applied to various LLM-based features and can help scope out the right kind of technical complexity:
Accuracy: Measures how often the LLM produces correct outputs. This is relevant for tasks like question answering, text classification, and sentiment analysis.
Precision: Measures the proportion of positive identifications (true positives) that are actually correct. Useful for tasks like information extraction and entity recognition.
Recall: Measures the proportion of actual positives that are identified correctly. This is complementary to precision and is useful for information extraction and entity recognition.
F1-score: Harmonic mean of precision and recall, providing a balance between the two. Often used as a single metric when precision and recall are both important.
Perplexity: Measures how surprised the LLM is by the input text. Lower perplexity indicates better understanding. Useful for evaluating language models' general language proficiency.
BLEU (Bilingual Evaluation Understudy): Compares generated text to reference translations. This is used for machine translation evaluation.
METEOR (Metric for Evaluation of Translation with Human Ordinal Reference): Similar to BLEU but incorporates more linguistic features.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Measures the overlap between generated text and reference summaries, useful for summarization tasks.
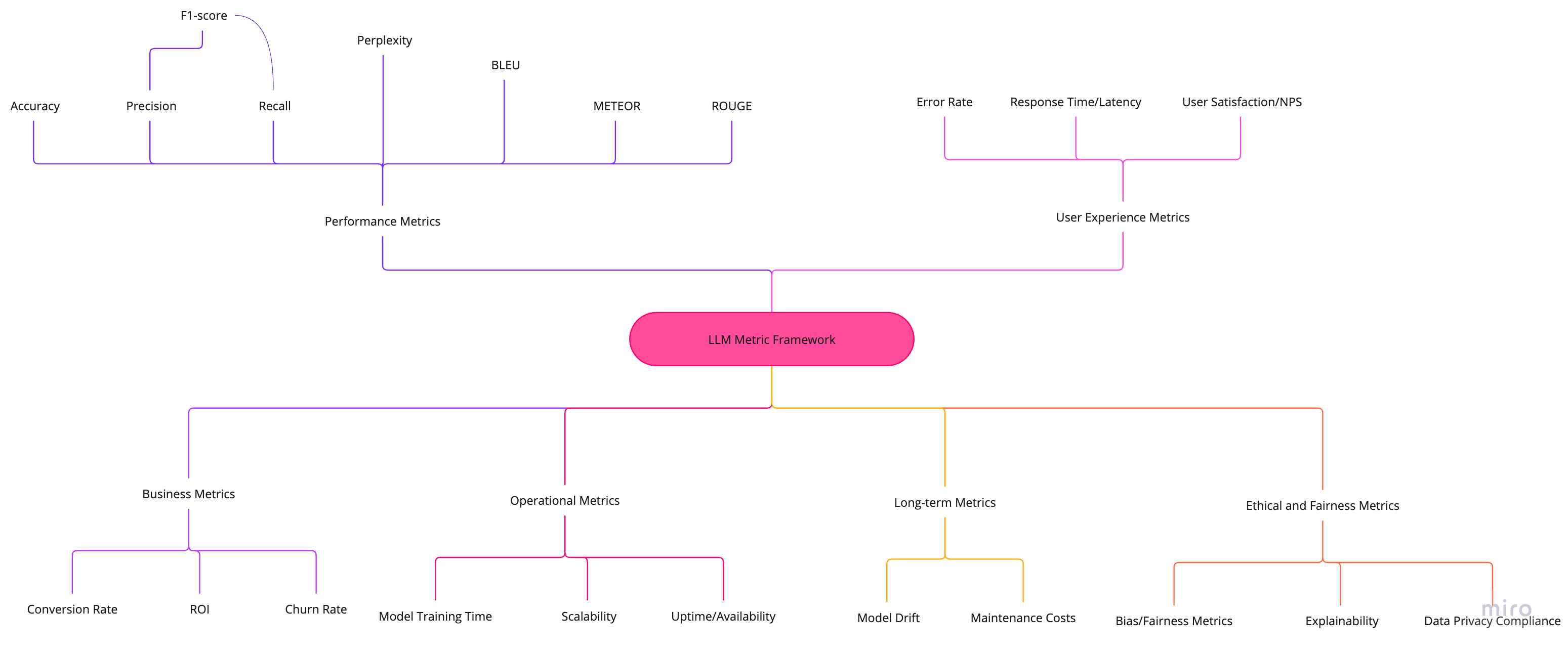
Business Metrics
Conversion Rate: For AI features driving actions (like recommendations), the percentage of users who complete the desired action.
Return on Investment (ROI): Measures the financial gain or loss generated by the AI feature relative to its cost.
Churn Rate: The percentage of users who stop using the AI feature, indicating its effectiveness and relevance.
User Experience Metrics
Response Time/Latency: Measures how quickly the AI feature responds to a user input.
User Satisfaction/Net Promoter Score (NPS): Qualitative metric to gauge user satisfaction with the AI feature.
Error Rate: Measures the frequency of errors or failures encountered by the user.
Operational Metrics
Model Training Time: The time it takes to train the AI model; crucial for models that need frequent updates.
Scalability: The ability of the AI feature to handle increased loads or datasets without performance degradation. Defined typically as p90, p95, or p50 measures.
Uptime/Availability: Measures the percentage of time the AI feature is operational and available for use. The industry standard is 99.99% uptime.
Ethical and Fairness Metrics
Bias/Fairness Metrics: Ensuring the AI feature does not disproportionately affect certain groups negatively. Most commonly measured using human correlation.
Explainability: The extent to which the AI model’s decisions can be understood by humans; crucial for user trust and in certain industries.
Data Privacy Compliance: This is not a metric, but important to call out if the AI feature adheres to data privacy regulations like GDPR or CCPA.
Long-term Metrics
Model Drift: Tracking changes in the model’s performance over time as data distribution changes.
Maintenance Costs: Ongoing costs associated with keeping the AI feature updated and performing well.
In the next part, we will go over an example of an AI PRD written using some of the information gathered using the above information gathering.
Hope this helps in getting started with your AI feature and make it successful in the market. :)
Cheers,
Richa
Your Chief Data Obsessor, The Data PM Gazette.
Great article, thanks!